Ci sono incredibili introduzioni, corsi e blog post sul Deep Learning. Ma questo è un tipo diverso di introduzione.

Ma perché strana? Forse perché non seguirà la struttura "normale" di una pubblicazione di Deep Learning, dove si inizia con la matematica, per poi passare agli articoli, all'implementazione e poi alle applicazioni.
A volte è importante avere un backup scritto dei propri pensieri. Tendo a parlare molto, ed essere presente in diverse presentazioni e conferenze, e questo è il mio modo di contribuire con un po' di conoscenza a tutti.
Il Deep Learning (DL) è un campo così importante per la Data Science, l'intelligenza artificiale, la tecnologia e la nostra vita in questo momento, e merita tutta l'attenzione che sta ricevendo. Per favore non dire che l'apprendimento profondo è solo l'aggiunta di uno strato ad una rete neurale, e questo è tutto, magia! No. Spero che dopo aver letto questo articolo tu abbia una prospettiva diversa di cosa sia DL.
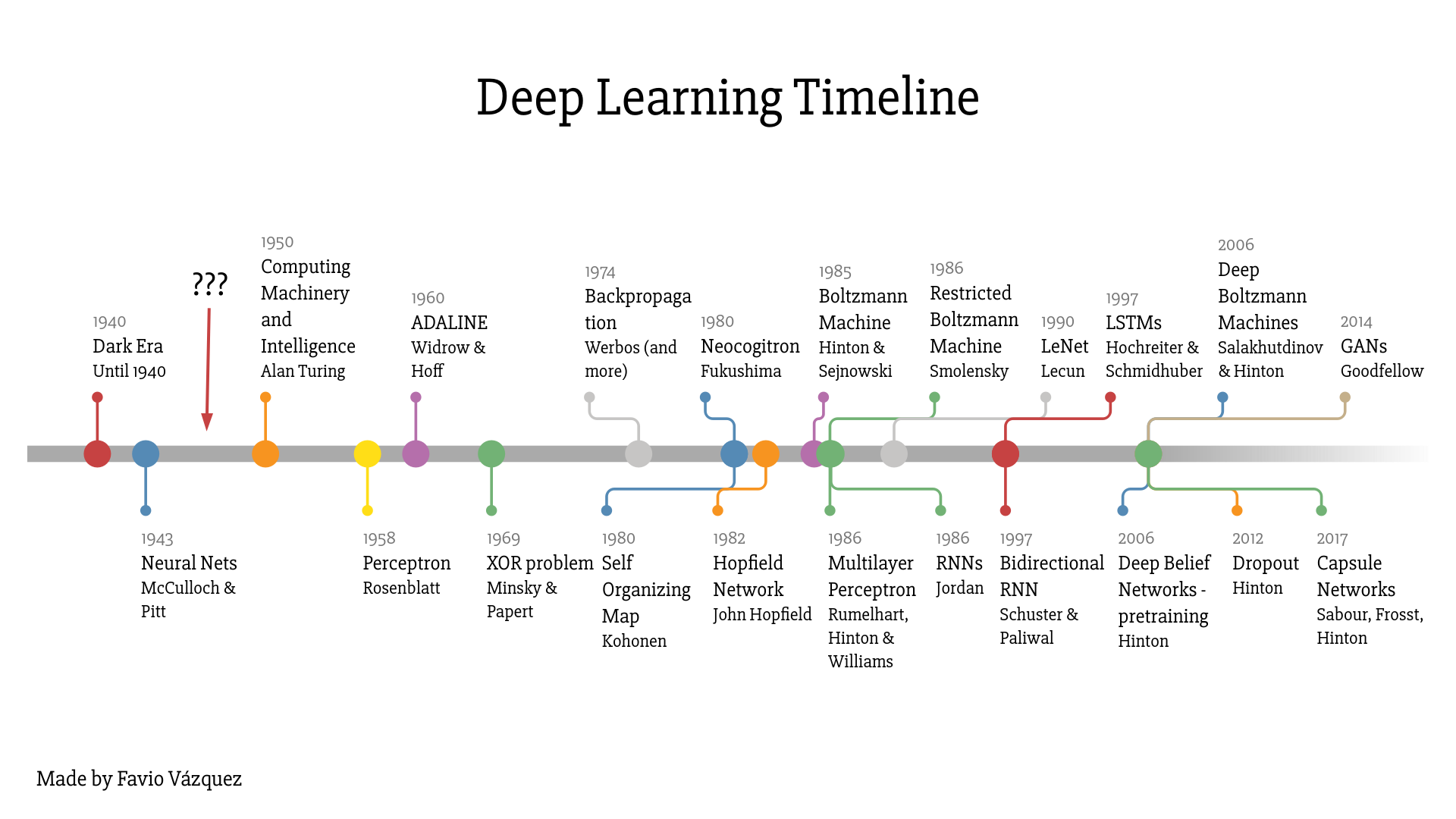
Ho appena creato questa linea temporale basata su diversi documenti e altre linee temporali con lo scopo di far capire a tutti che Deep Learning è molto più di una semplice rete neurale. Ci sono stati davvero progressi teorici, miglioramenti software e hardware che ci sono stati necessari per arrivare a questo giorno. Se vuoi, basta un ping me e te lo manderò. (Trova il mio contatto alla fine dell'articolo).
Cosa c'è di strano nel DL
Il Deep Learning è in circolazione da un bel po' di tempo. Allora perché è diventato così importante così velocemente negli ultimi 5-7 anni?
Come ho detto prima, fino alla fine degli anni 2000, ci mancava ancora un modo affidabile per addestrare reti neurali molto profonde. Al giorno d'oggi, con lo sviluppo di diversi semplici ma importanti miglioramenti teorici e algoritmici, i progressi nell'hardware (soprattutto GPU, ora TPU), e la generazione e l'accumulo esponenziale di dati, DL è venuto naturalmente per adattarsi a questo punto mancante per trasformare il nostro modo di fare machine learning.
Deep Learning è un campo attivo di ricerca troppo, niente è risolto o chiuso, siamo ancora alla ricerca dei migliori modelli, topologia delle reti, modi migliori per ottimizzare i loro iperparametri e altro ancora. E 'molto difficile, come qualsiasi altro campo attivo sulla scienza, per tenersi aggiornati con l'indagine, ma non è impossibile.
Una nota a margine sulla topologia e l'apprendimento automatico (Deep Learning with Topological Signatures di Hofer et al.):
Questo per me è strano, o non comune perché normalmente bisogna aspettare qualche tempo (qualche anno) per essere in grado di digerire informazioni difficili e avanzare in articoli o riviste di ricerca. Naturalmente, la maggior parte delle aree della scienza sono ora davvero veloci anche per passare da un documento a un post di un blog che ti dice quello che devi sapere, ma a mio parere DL ha un'altra sensazione.
Innovazioni dell'apprendimento profondo e dell'apprendimento di rappresentazione
Stiamo lavorando con qualcosa che è molto eccitante, la maggior parte delle persone sul campo sta dicendo che le ultime idee nei lavori di apprendimento profondo (in particolare nuove topologie e configurazioni per NN o algoritmi per migliorare il loro utilizzo) sono le migliori idee in Machine Learning in decenni (ricordate che DL è all'interno di ML).
Ho usato molto la parola apprendimento in questo articolo finora. Ma cos'è l'apprendimento?
Nel contesto del Machine Learning, la parola "apprendimento" descrive un processo di ricerca automatica per una migliore rappresentazione dei dati che state analizzando e studiando (per favore tenete questo in mente, non è far apprendere un computer).
Questa è una parola molto importante per questo campo, REP-RE-SEN-TA-TION. Non dimenticarlo. Che cos'è una rappresentazione? È un modo di guardare i dati.
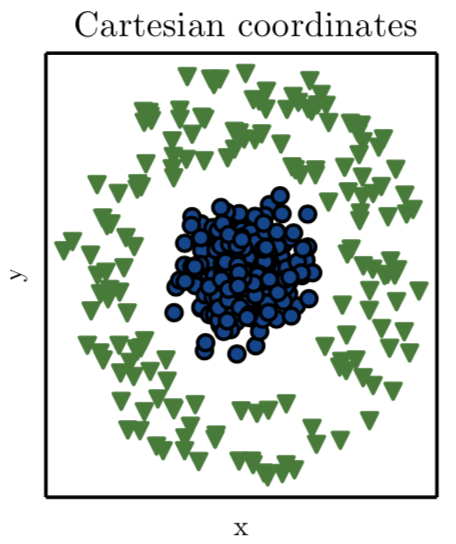
Permettetemi di farvi un esempio, diciamo che vi dico che voglio che guidiate una linea che separa i cerchi blu dai triangoli verdi per questa trama:
Quindi, se si vuole usare una linea, questo è ciò che dice l'autore del libro Deep Learning di Ian Goodfellow, et al. (2016):
ora si che è facile disegnare una linea che divide blu e verdi
Così, in questo semplice esempio abbiamo trovato e scelto la trasformazione per ottenere una migliore rappresentazione manuale. Ma se creiamo un sistema, un programma che può cercare diverse rappresentazioni (in questo caso un cambio di coordinate), e poi trovare un modo di calcolare la percentuale di categorie classificate correttamente con questo nuovo approccio, in quel momento stiamo facendo Machine Learning.
Questo è qualcosa di molto importante da avere in mente, l'apprendimento profondo è l'apprendimento di rappresentazione utilizzando diversi tipi di reti neurali e ottimizzare gli iperparametri della rete per ottenere (imparare) la migliore rappresentazione per i nostri dati.
l'articolo continua qui, quando ho tempo finisco la traduzione
di Favio Vàzquez
l'articolo originale lo trovate qui: https://towardsdatascience.com/
Ma perché strana? Forse perché non seguirà la struttura "normale" di una pubblicazione di Deep Learning, dove si inizia con la matematica, per poi passare agli articoli, all'implementazione e poi alle applicazioni.
A volte è importante avere un backup scritto dei propri pensieri. Tendo a parlare molto, ed essere presente in diverse presentazioni e conferenze, e questo è il mio modo di contribuire con un po' di conoscenza a tutti.
Il Deep Learning (DL) è un campo così importante per la Data Science, l'intelligenza artificiale, la tecnologia e la nostra vita in questo momento, e merita tutta l'attenzione che sta ricevendo. Per favore non dire che l'apprendimento profondo è solo l'aggiunta di uno strato ad una rete neurale, e questo è tutto, magia! No. Spero che dopo aver letto questo articolo tu abbia una prospettiva diversa di cosa sia DL.
Ho appena creato questa linea temporale basata su diversi documenti e altre linee temporali con lo scopo di far capire a tutti che Deep Learning è molto più di una semplice rete neurale. Ci sono stati davvero progressi teorici, miglioramenti software e hardware che ci sono stati necessari per arrivare a questo giorno. Se vuoi, basta un ping me e te lo manderò. (Trova il mio contatto alla fine dell'articolo).
Cosa c'è di strano nel DL
Il Deep Learning è in circolazione da un bel po' di tempo. Allora perché è diventato così importante così velocemente negli ultimi 5-7 anni?
Come ho detto prima, fino alla fine degli anni 2000, ci mancava ancora un modo affidabile per addestrare reti neurali molto profonde. Al giorno d'oggi, con lo sviluppo di diversi semplici ma importanti miglioramenti teorici e algoritmici, i progressi nell'hardware (soprattutto GPU, ora TPU), e la generazione e l'accumulo esponenziale di dati, DL è venuto naturalmente per adattarsi a questo punto mancante per trasformare il nostro modo di fare machine learning.
Deep Learning è un campo attivo di ricerca troppo, niente è risolto o chiuso, siamo ancora alla ricerca dei migliori modelli, topologia delle reti, modi migliori per ottimizzare i loro iperparametri e altro ancora. E 'molto difficile, come qualsiasi altro campo attivo sulla scienza, per tenersi aggiornati con l'indagine, ma non è impossibile.
Una nota a margine sulla topologia e l'apprendimento automatico (Deep Learning with Topological Signatures di Hofer et al.):
I metodi della topologia algebrica sono emersi solo di recente nella comunità dell'apprendimento automatico, soprattutto con il termine "analisi dei dati topologici (TDA)". Poiché TDA ci permette di dedurre informazioni topologiche e geometriche rilevanti dai dati, può offrire una prospettiva nuova e potenzialmente vantaggiosa sui vari problemi di machine learning.Fortunatamente per noi, ci sono molte persone che aiutano a capire e digerire tutte queste informazioni attraverso corsi come quello di Andrew Ng, blog post e molto altro ancora.
Questo per me è strano, o non comune perché normalmente bisogna aspettare qualche tempo (qualche anno) per essere in grado di digerire informazioni difficili e avanzare in articoli o riviste di ricerca. Naturalmente, la maggior parte delle aree della scienza sono ora davvero veloci anche per passare da un documento a un post di un blog che ti dice quello che devi sapere, ma a mio parere DL ha un'altra sensazione.
Innovazioni dell'apprendimento profondo e dell'apprendimento di rappresentazione
Stiamo lavorando con qualcosa che è molto eccitante, la maggior parte delle persone sul campo sta dicendo che le ultime idee nei lavori di apprendimento profondo (in particolare nuove topologie e configurazioni per NN o algoritmi per migliorare il loro utilizzo) sono le migliori idee in Machine Learning in decenni (ricordate che DL è all'interno di ML).
Ho usato molto la parola apprendimento in questo articolo finora. Ma cos'è l'apprendimento?
Nel contesto del Machine Learning, la parola "apprendimento" descrive un processo di ricerca automatica per una migliore rappresentazione dei dati che state analizzando e studiando (per favore tenete questo in mente, non è far apprendere un computer).
Questa è una parola molto importante per questo campo, REP-RE-SEN-TA-TION. Non dimenticarlo. Che cos'è una rappresentazione? È un modo di guardare i dati.
Permettetemi di farvi un esempio, diciamo che vi dico che voglio che guidiate una linea che separa i cerchi blu dai triangoli verdi per questa trama:
 |
| Ian Goodfellow et al. (Deep Learning, 2016) |
Quindi, se si vuole usare una linea, questo è ciò che dice l'autore del libro Deep Learning di Ian Goodfellow, et al. (2016):
rappresentando i dati con coordinate cartesiane, il compito è impossibileQuesto è impossibile se ricordiamo il concetto di una linea:
Una linea è una figura monodimensionale diritta, priva di spessore e che si estende all'infinito in entrambe le direzioni.Quindi il caso è perduto? In realtà no. Se troviamo un modo di rappresentare questi dati in modo diverso, in modo da poter tracciare una linea retta per separare i tipi di dati. Questo è qualcosa che la matematica ci ha insegnato centinaia di anni fa. In questo caso ciò di cui abbiamo bisogno è una trasformazione di coordinate, in modo da poter tracciare o rappresentare questi dati in modo da poter tracciare questa linea. Se guardiamo la trasformazione delle coordinate polari, abbiamo la soluzione:
 |
| Ian Goodfellow et al. (Deep Learning, 2016) |
ora si che è facile disegnare una linea che divide blu e verdi
Così, in questo semplice esempio abbiamo trovato e scelto la trasformazione per ottenere una migliore rappresentazione manuale. Ma se creiamo un sistema, un programma che può cercare diverse rappresentazioni (in questo caso un cambio di coordinate), e poi trovare un modo di calcolare la percentuale di categorie classificate correttamente con questo nuovo approccio, in quel momento stiamo facendo Machine Learning.
Questo è qualcosa di molto importante da avere in mente, l'apprendimento profondo è l'apprendimento di rappresentazione utilizzando diversi tipi di reti neurali e ottimizzare gli iperparametri della rete per ottenere (imparare) la migliore rappresentazione per i nostri dati.
l'articolo continua qui, quando ho tempo finisco la traduzione
di Favio Vàzquez
l'articolo originale lo trovate qui: https://towardsdatascience.com/
Commenti